Stop Building Gorgeous Chaos
More context won’t help if the cockpit is a pop-up ad storm.
Picture this: An autopilot running a repair mission on a massive space station. Halfway through, it forgets what it was trying to fix. Every sensor reading, every failed attempt, every status update, all piled into one endless scroll until the original mission objective got buried under an avalanche of its own telemetry. The autopilot is still brilliant. But its cockpit has become unreadable.

Here’s what makes this genuinely fascinating: a weaker model with better scaffolding can beat a stronger one. In recent benchmarks, a smaller Claude model with the right operational infrastructure outperformed a larger one with mediocre ops. Same evaluation harness, same benchmark. The difference was how information flowed to the AI.
We’ve been obsessing over engine horsepower when the bottleneck is cockpit design. The Confucius Code Agent paper makes that painfully clear, and the best way to understand it is to imagine you’re running a space station, not a coding agent.
Three Control Rooms: The Insight That Changes Everything
Before we tour the station, you need to understand the paper’s core breakthrough. It’s almost embarrassingly simple once you see it.

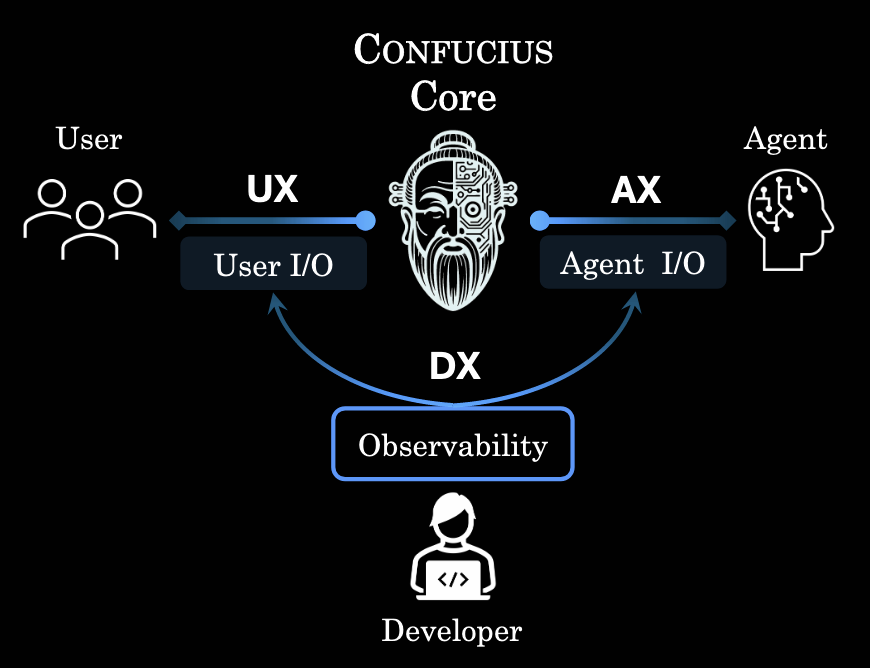
There are three audiences for any agent system, and they need completely different views of what’s happening.
- AX (Autopilot Cockpit): Must be clean and focused. If you plaster the AI’s screen with verbose logs, raw telemetry, and color-coded human comments, it gets confused and makes worse decisions. The autopilot needs distilled state: key goals, important events, current subtasks. Nothing more.
- UX (Mission Control Displays): Serves humans who need detailed timelines, rich logs, diffs, graphs, and warnings. They want to see “We tried patch X at 14:32” and “Tests failed here” and “Now editing subsystem Y.” For humans, more detail is often better.
- DX (Engineering Workshop): Where station operations engineers inspect historical mission traces, run simulations, swap out modules, and tune prompts. They need observability into both what the autopilot saw and what humans saw.
The catastrophic mistake most frameworks make is conflating these three. They take the verbose Mission Control log, designed for human readability, and feed it directly into the autopilot’s panel. The autopilot’s screen becomes a mess, so it makes worse decisions. The human display gets trimmed to save tokens, so humans lose visibility. And developers can’t easily tell which information was meant for whom.
The Confucius SDK’s rule is elegant: different views for different decks. Every mechanism that follows serves one or more of these three audiences. Keep AX, UX, and DX in mind as we walk through the architecture.
The Station: Your Codebase as Orbital Infrastructure
Now picture a sprawling orbital station with thousands of modules: docking bays, laboratories, life support systems, cargo holds. That’s your real world codebase. Thousands of files, services, tests, configurations, all interconnected in ways that nobody fully remembers.

There’s always one config flag that breaks France if you remove it, and nobody knows why. That’s exactly the kind of institutional memory your ops layer needs to preserve.
Missions arrive constantly.
- Fix a leak in Bay 7.
- Upgrade the reactor.
- Reroute power from Section C to Section D.
In software terms: bug fixes, feature requests, refactors. Each mission requires understanding how distant parts of the station connect, coordinating multiple repair crews, and not accidentally venting atmosphere into space while you’re at it.
The question isn’t whether your autopilot AI is smart enough to handle these missions. Modern LLMs clearly are. The question is whether your operations system gives that autopilot the right AX: clean, focused, structured information that enables good decisions.
This brings us to the first mechanism.
The Compressor: Keeping Long Missions Coherent
Left unchecked, a long debugging session produces gigantic mission logs. Hundreds of telemetry messages. Many attempts, failures, partial fixes. If you feed all of this into the autopilot every cycle, its main screen becomes an unreadable wall of text. This is an AX problem: the agent’s working context has become polluted.
The solution is what the paper calls the Architect agent, but I’ll call it the Compressor to avoid confusion with a different component we’ll meet later. The Compressor steps in when the autopilot’s cockpit screen risks overflowing its token limit.
Its job is surgical. It looks at older parts of the mission history and produces a structured summary: mission goals, key decisions, important failures and error traces, remaining TODOs. Then it replaces those long old logs with this compressed mission summary while keeping the last few turns of detailed logs intact.
Think of it as someone periodically saying: “Let me shrink older tapes into a concise mission record, so you still see what matters without clutter.”
In ablation studies, enabling this hierarchical context management accounted for roughly 6.6 percentage points of improvement (48.6% with compression versus 42.0% without) on the same benchmark subset. That gain comes purely from better information architecture.
But context management within a single mission is only half the problem. What happens across missions?
The Logkeeper: Learning Without Retraining
Space stations run for years. You need permanent logbooks: incident reports, lessons learned documents, scenario specific guides. This serves both AX (the agent can retrieve past knowledge) and UX (humans can read and audit what the agent learned).
The Logkeeper is a dedicated note taking agent that runs after each mission. It looks at the full trajectory, what the agent tried, tools invoked, success or failure outcomes, and writes structured Markdown notes into a file tree organized by project and shared patterns.
The crucial innovation is the emphasis on hindsight notes for failures. The system records not just successful solutions but compilation errors, runtime exceptions, and unproductive strategies, together with eventual resolutions or reasons for abandonment.
So when a similar failure appears in a future mission, the agent can query: “Do we have any incident reports about this?” If found, the relevant note is surfaced into working memory. What would have been a from scratch debugging session becomes a “seen before” scenario.
Running the same benchmark issues twice, once cold and once with notes from the first run, showed reduced steps (64 to 61 turns), reduced token usage (104k to 93k), and slightly improved success rates (53% to 54.4%). The station effectively learns operationally across missions without retraining the model.
This matters because most discussions of AI memory focus on fine tuning or retrieval augmented generation. The Confucius approach is different: structured, human readable Markdown files that accumulate domain expertise the way a real engineering team would document institutional knowledge. It’s not magic. It’s good ops.
The Configurator: Agents That Build Other Agents
Now imagine you want to deploy new operations setups: one for handling CI failures, another for refactoring huge monorepos, another for read only analysis in sensitive environments. You could hand write their configurations. Or you could ask a meta agent I’ll call the Configurator.
A developer describes the desired configuration in natural language: “An agent that triages CI failures with read only access to configs and full test execution.” The Configurator translates that into a structured spec, synthesizes the agent’s configuration and prompts, wires in the selected extensions and memory policies, then tests the new agent against representative tasks.
When failures or undesirable behaviors are detected (brittle tool selection, incorrect file edit patterns, poor recovery from compiler errors), the Configurator proposes modifications. These patches are applied, and the test loop reruns. It’s a build, test, improve cycle for agent configurations themselves.
This is pure DX: making it easier for developers to create, debug, and iterate on agents. The production Confucius Code Agent is itself the outcome of this loop. The researchers didn’t hand craft it from scratch. They started with a high level description, let the Configurator synthesize the initial configuration, then repeatedly refined it against a production grade test set until performance stabilized.
The resulting agent exhibits more reliable tool selection and recovery behaviors than initial hand written designs. When the paper reports tool use ablations, they’re literally swapping which modules the Configurator assembled, while holding the core orchestrator fixed.
What the Benchmarks Actually Show
Here’s what happens when you build mission control instead of just upgrading the autopilot.
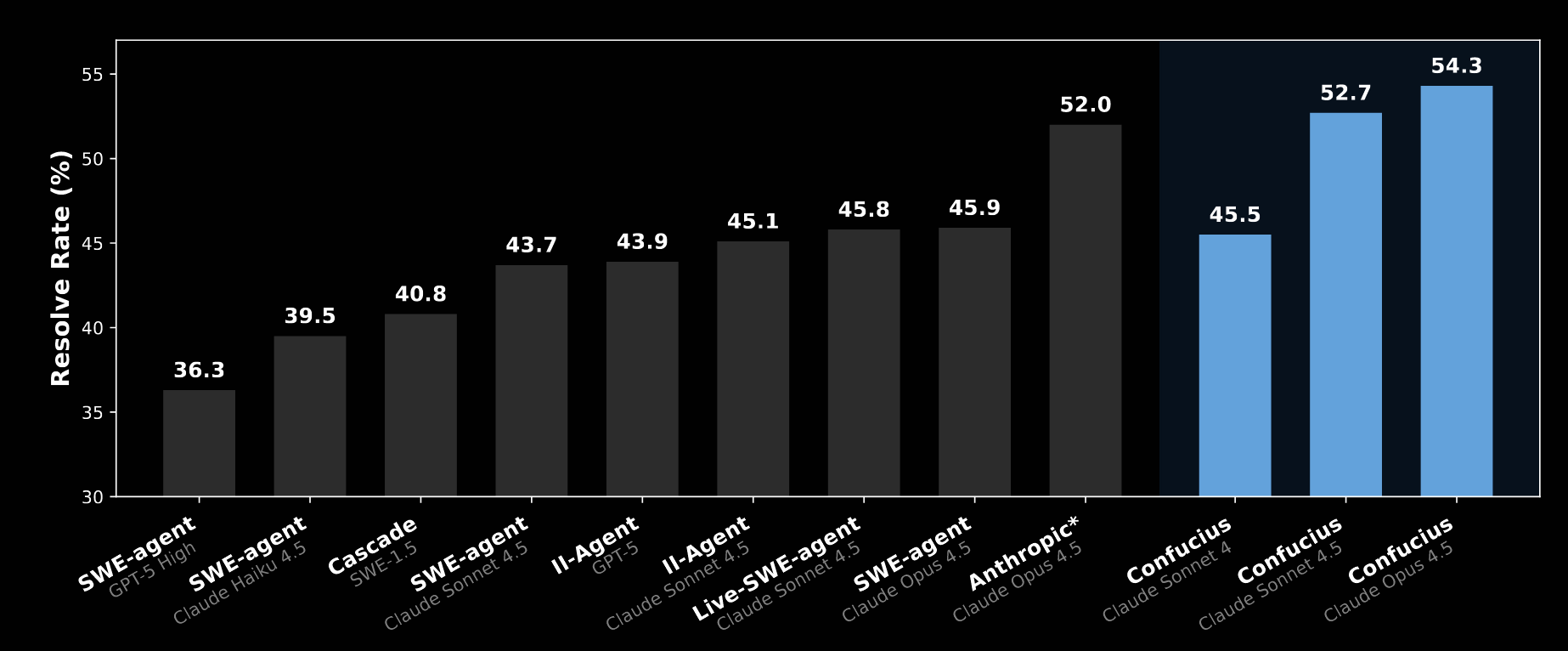
On SWE Bench Pro, a collection of 731 real GitHub issues requiring agents to produce patches that pass all repository tests:
- Confucius + mid tier model (Sonnet 4.5): 52.7% resolution
- Baseline scaffold + mid tier model: 43.6% resolution
- Confucius + larger model (Opus 4.5): 54.3% resolution
- Baseline scaffold + larger model: 52.0% resolution
That 9+ percentage point improvement for the mid tier model comes purely from better scaffolding. Same engine. Better cockpit. More successful landings.
Even more striking: the smaller model plus Confucius (52.7%) beats the larger model plus baseline scaffolding (52.0%). A weaker autopilot with better operations outperforms a stronger autopilot with mediocre operations.
Ablations make the causality clean:
- Compressor: accounts for roughly 6.6 points of improvement
- Configurator: removing learned tool conventions causes large performance drops, even when context management is preserved
- Logkeeper: saves roughly 11k tokens per task while slightly improving success rates
These aren’t marginal gains from prompt tweaking. They’re architectural wins from treating AX, UX, and DX as first class design concerns.
Scaffolding Is Architecture, Not Plumbing
We’ve spent years in an arms race for smarter autopilots. Bigger models, more training data, better RLHF. And those investments matter.
But this research suggests we’ve been underinvesting in the operations layer. The cockpit design. The mission control infrastructure. The logbooks and incident reports.
The Confucius team argues that addressing challenges like long context reasoning and long term memory requires more than longer context windows or larger models. It requires a principled approach to how agents structure, maintain, and interact with external information.
We’ve been treating scaffolding as plumbing, boring infrastructure that just needs to work well enough to not get in the way of the brilliant AI. But scaffolding determines what the AI can see, what it can remember, and what tools it can reach for. That’s not plumbing. That’s architecture.
The Real Mission
The space station analogy isn’t just pedagogically convenient. It captures something essential about where AI agent development is headed. We’re not building isolated programs anymore. We’re building operational systems that need to coordinate reasoning, tools, memory, and human oversight across long horizons and massive codebases.
The three audiences framework (AX, UX, and DX) isn’t specific to coding agents. Any AI system that needs to maintain coherent reasoning over long sessions, accumulate knowledge across tasks, and remain inspectable to humans could benefit from this architecture. Customer service bots. Research assistants. Autonomous vehicles. The pattern generalizes.
In a world where foundation models become increasingly commoditized, the competitive moat might not be who has the smartest autopilot. It might be who builds the best space station.
We’ve poured billions into model training. The neglected variable is the operational infrastructure that determines whether those models can think clearly. So here’s the uncomfortable question: are we trying to make the AI smarter, when we should be making its environment more legible?